杠杆炒股,股票融资!

中国大模子又在包括硅谷在内的巨匠AI圈炸场了。
两天前,幻方量化旗下AI公司深度求索(DeepSeek),以及月之暗面相隔20分钟接踵发布了自家最新版推理模子,分歧是DeepSeek-R1以及Kimi 全新多模子念念考模子k1.5,且齐给出了零散详备的时期讲演, “中国双子星”很快激勉巨匠AI圈的温雅。
在酬酢软件X上,包括英伟达AI科学家Jim Fan在内的巨匠AI从业者纷纷发出了我方的齰舌:
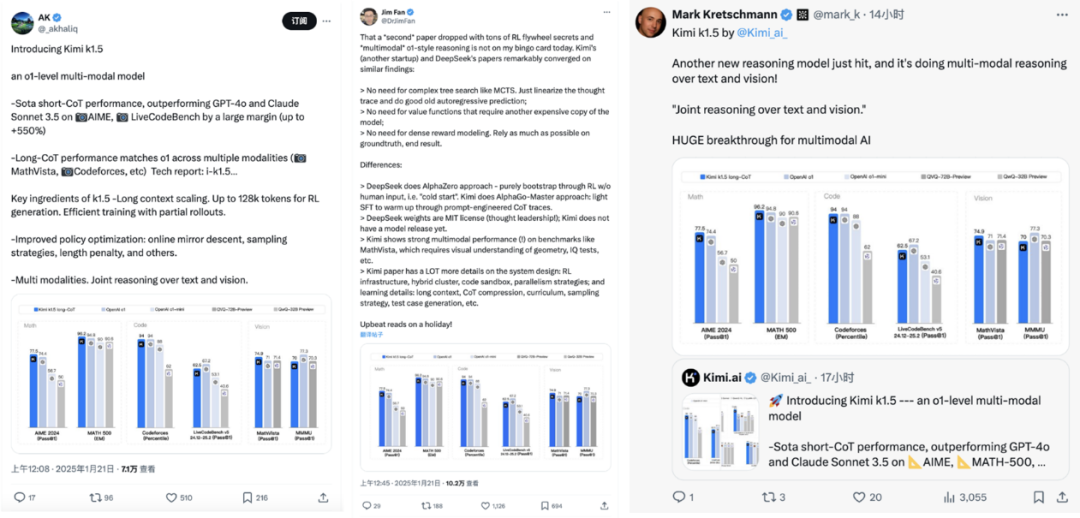
干悉数据炫耀,区别于过往类o1-preview模子,此次两家中国公司正面硬刚OpenAI o1,发布的齐是满血版o1,而Kimi k1.5照旧具备视觉念念考的多模态。
名义上,是中国大模子某种程度上又一次在时期能力上直起了腰,而巨匠AI从业者的“围不雅”,实质上则表示出业界对大模子这台“蒸汽机”大略尽快出现属于我方的“瓦特”的生机。
01
大模子这台蒸汽机,急需要一个“瓦特”
大模子对时间的意念念,不亚于蒸汽机之于工业翻新。
但正如蒸汽机是在发明之后,是经过一段时候的改进,尤其是瓦特的改进后才正在成为工业翻新驱能源一样,大模子这台“蒸汽机”要想大展拳脚,还一直处在继续改进之中。
阿谁属于它的“瓦特”,还一直莫得到来,整个从业者齐在报复期待这个时刻。
参与的东谈主越多,“瓦特时刻”出现的可能性就越大,惟有一个遥遥首先的OpenAI有时相宜业界的多半生机,当出现了与之肩并肩的DeepSeek、Kimi,要道进化的可能性变得更大,炸场AI圈就成为多半期待下的势必。

而回看DeepSeek与Kimi这对中国双子星,他们发布的模子呈现了好多相似之处,齐侧重以强化学习(RL)为中枢驱能源(即在仅有少量标注数据的情况下,极大进步模子推理能力)。
具体来说,二者在结束方式上齐不需要进行像 MCTS 那样复杂的树搜索(只需将念念维轨迹线性化,然后进行传统的自总结接洽即可),也不需要设立另一个立志的模子副本的价值函数、不需要密集奖励建模,只尽可能多的依坏事实和最终限制。
很昭彰,这些,齐在进步推理模子的启动遵守、训斥资源需求,而挑升念念的是,这一样是昔日瓦特改进蒸汽机的主义,他在繁密改进中最好意思满地结束了这些主义。
历史,老是惊东谈主的相似。
值得一提的是,在此次中国双子星炸场的经过中,OpenAI萨姆·奥尔特曼也加入其中,只不外他施展了一贯的“阴阳”技巧,“AGI不会下个月就到来”,在一派赞叹以至狂欢中,背地里讪笑酬酢平台的温雅是不是太过荒诞。
试验上,AGI如实不是短期能作念到的,但这并不是制止巨匠从业者郁勃饱读吹的原理。蒸汽机花了很永劫候才完成进化大略走入工场,大模子也需要这么的经过才能结束对社会跳跃的全面赋能,也正因为如斯,每一次对这个程度的镌汰,齐值得每一个从业者喜跃。
02
中国双子星,让业界看到“瓦特”的更多可能性
具体到时期层面,当仔细分析中国双子星尤其是Kimi的SOTA模子能力后,就会发现业界东谈主士的惊喜有着充分的原理。
以“蒸汽机”类比,瓦特的改进首先是平直进步了启动遵守,进步了蒸汽蜕变为机械能源的能力,从而大略由“练习安装”走向的确的“机器”。
此次发布的模子首先亦然在推理能力上大幅跨越,发布的齐是的确的“满血版o1”,而不是其他各家所发布的“准o1”,或者得分差得太远的o1,有着统统实力上的首先而非只是小小的一次迭代。
更进一步看,瓦特对蒸汽机的改进还在机器对不同出产环境的恰当能力上进行了改进,股市配资对应到大模子这里,则是推理大模子的多模态进化。
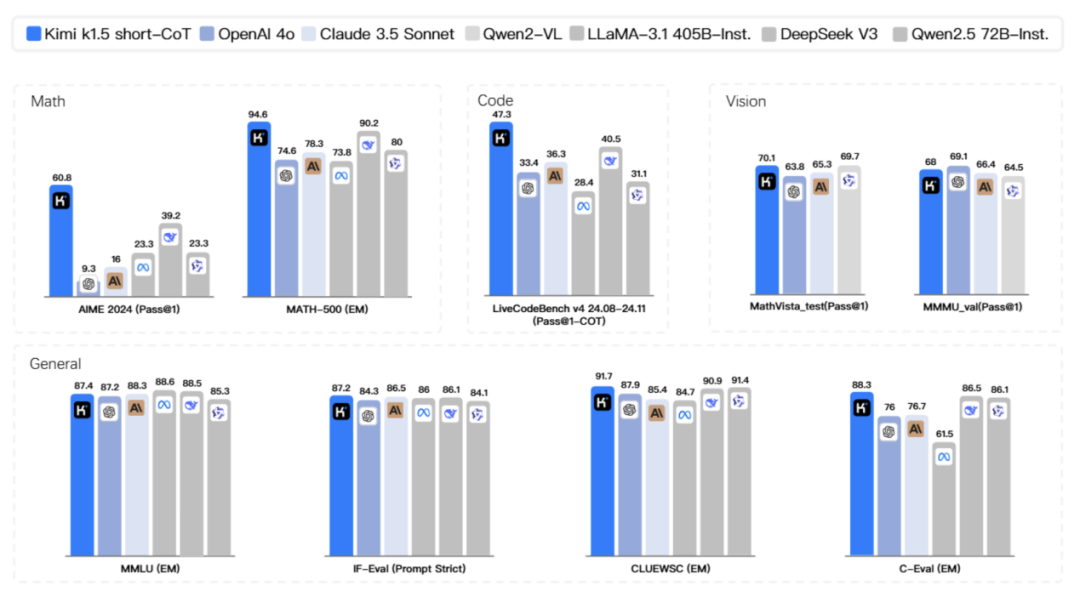
现在,DeepSeek R1只可识别笔墨、不赈济图片识别不同,Kimi k1.5则能进行一步多模态推理,且在数学、代码、视觉等复杂任务上的概括性能进步,成为OpenAI以外首个多模态类o1模子。
以Kimi k1.5为例:
一方面模子在数学和代码能力上的推理能力和正确率(诸如 pass@1、EM等主义)大幅首先或赶超其他主流对比模子;
另一方面模子在在视觉多模态任务上,不管是对图像中信息的意会、照旧进一步的组合推理、跨模态推理能力,齐有显耀进步。
截取Kimi的发布Paper原文,其长文本搞定能力大幅进步,赈济高达128ktokens 的 RL生成,给与部分张开方式进行高效教授,且在教授计谋上有包括在线镜像下落法等在内的多项改进。
在长念念考模式(long-CoT)下,Kimi K1.5在数学、编程和视觉任务中的发达与OpenAI o1的性能水平接近。
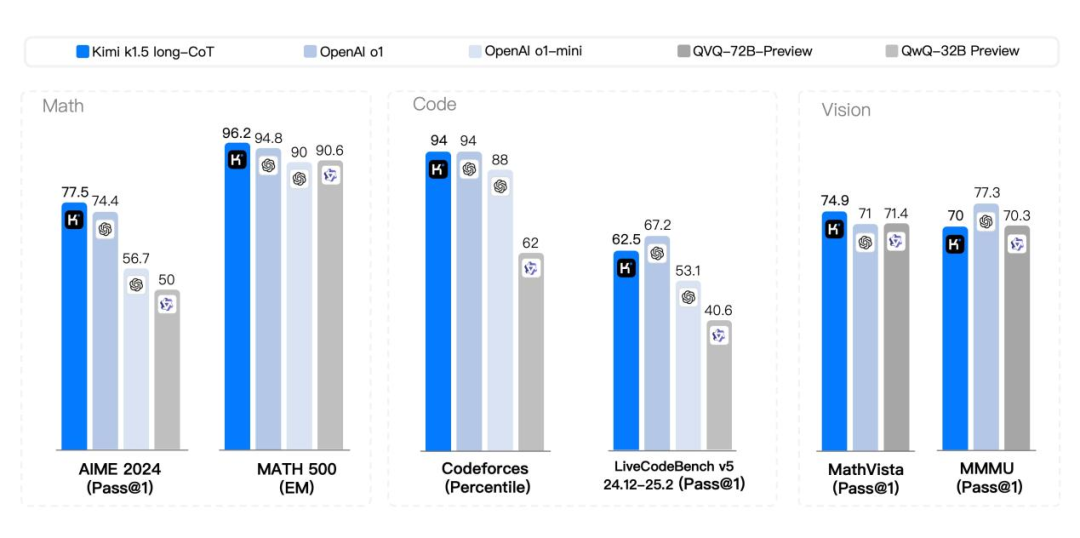
而到了短念念考模式(short-CoT)下,Kimi k1.5 更是让业界惊喜,作念到了某种程度上的“遥遥首先”,其数学、代码、视觉多模态和通用能力,大幅卓越了巨匠范围内短念念考SOTA模子GPT-4o和Claude 3.5 Sonnet的水平,首先达到550%。
这种首先,收成于Kimi k1.5特有的“Long2Short”教授决策,顾名念念义,即先行使较大的险峻文窗口让模子学会长链式念念维,再将“长模子”的遵守和参数与更小、更高效的“短模子”进行归拢,然后针对短模子进行格外的强化学习微调。
这种作念法,最大化保留了原先长模子的推理能力,幸免了常见的“精简模子后能力缩小”繁难,又能同期有用挖掘短模子在特定场景下的高效推理或部署上风,是一次推理模子的要紧创新。
“Long2Short”教授决策在算力与性能均衡方面结束了奏效探索,改变了OpenAI o1以时候换空间的作念法(摈弃试验应用时的用户体验来进步性能,这种作念法一直存在争议),有业界东谈主士暗意将会是异日新的磋磨主义。
而从更宏不雅的视角看,这么的创新,除了给Kimi带来更亮眼的模子发达,毫无疑问也在让大模子“蒸汽机”的“瓦特时刻”变得越来越近。
03
更密集的冲突,才能争抢“瓦特”
Kimi k1.5的出现显着不会是一蹴而就的,是屡次进化迭代的限制,但最令东谈主温雅的,是迭代的速率。
只是在三个月前的2024年11月,月之暗面就推出了初代版块的Kimi K0-math。过了1个月,k1视觉念念考模子出身,汲取了K0-math的数学能力,又奏效解锁了视觉意会能力,“会算”+“会看”。紧接着又1个月后,也等于此次的K1.5发布,在数理化、代码、通用等多个鸿沟中,刷新了SOTA,平直失色寰球顶尖模子。
三个月三次冲突,密集创新迭代才带来炸场的效果与遵守。
在要道的历史节点,业界期待“瓦特”,与此同期,业界也在争当“瓦特”,大模子只会越来越卷。
就在中国双子星炸场后,好意思国总统特朗普告示OpenAI、甲骨文和软银将聚首鼓舞一项称之为Stargate(星际之门)的款式,要在东谈主工智能基础形势鸿沟投资至少5000亿好意思元,大国AI竞争仍是尖锐化。
好在,不管是基础形势的建造,还所以中国双子星为代表的模子能力建造,中国齐仍是霸占了先机,这一次不会再处于被迫地位——在Kimi的探讨中,其将连接发力多模态推理,快速迭代出更多模特、更多鸿沟、更具备通用能力的Kn系列模子。
礼服,大模子的“瓦特时刻”,一样会是中国大模子获得语言权的时刻。