杠杆炒股,股票融资!

传闻,当今也曾有东说念主在搞十万卡集群了!
什么倡导呢?100000张GPU或者AI加速卡攒在沿途,组团干活,提供“核弹级”算力。

这样顶,真有必要吗?必须有,业界大佬都在这样干!
只因AGI太火爆,激勉了算力“武备竞赛”,十万卡集群也曾成为业界顶尖大模子公司的标配,xAI、Meta、OpenAI都在搞!

即便大众如斯激进,算力瓶颈仍然拖了大模子迭代的后腿。
坊间传闻,GPT5迟迟不可发布的原因之一,就是算力不及。

而国内的头部大模子厂商,也都在彼此较劲,紧锣密饱读地筹建十万卡集群…
总之,趋势在那边摆着,算力基础活动必须要跟上,“不搞就会过期,过期就要挨揍”!

“十万卡”集群,有多难搞?
领先,你懂的,家里如实要有矿!
一台8卡就业器,十万卡就是12500台就业器,这就是250亿了。
是以,十万卡集群,都是巨头或者拿到精深投资的公司在搞。

然而,关于国内企业来说,光“家里有矿”还不够,第一说念技巧坎就把大众卡住了。
这说念坎就是:十万卡领域的智算中心,必须要跨地域部署。
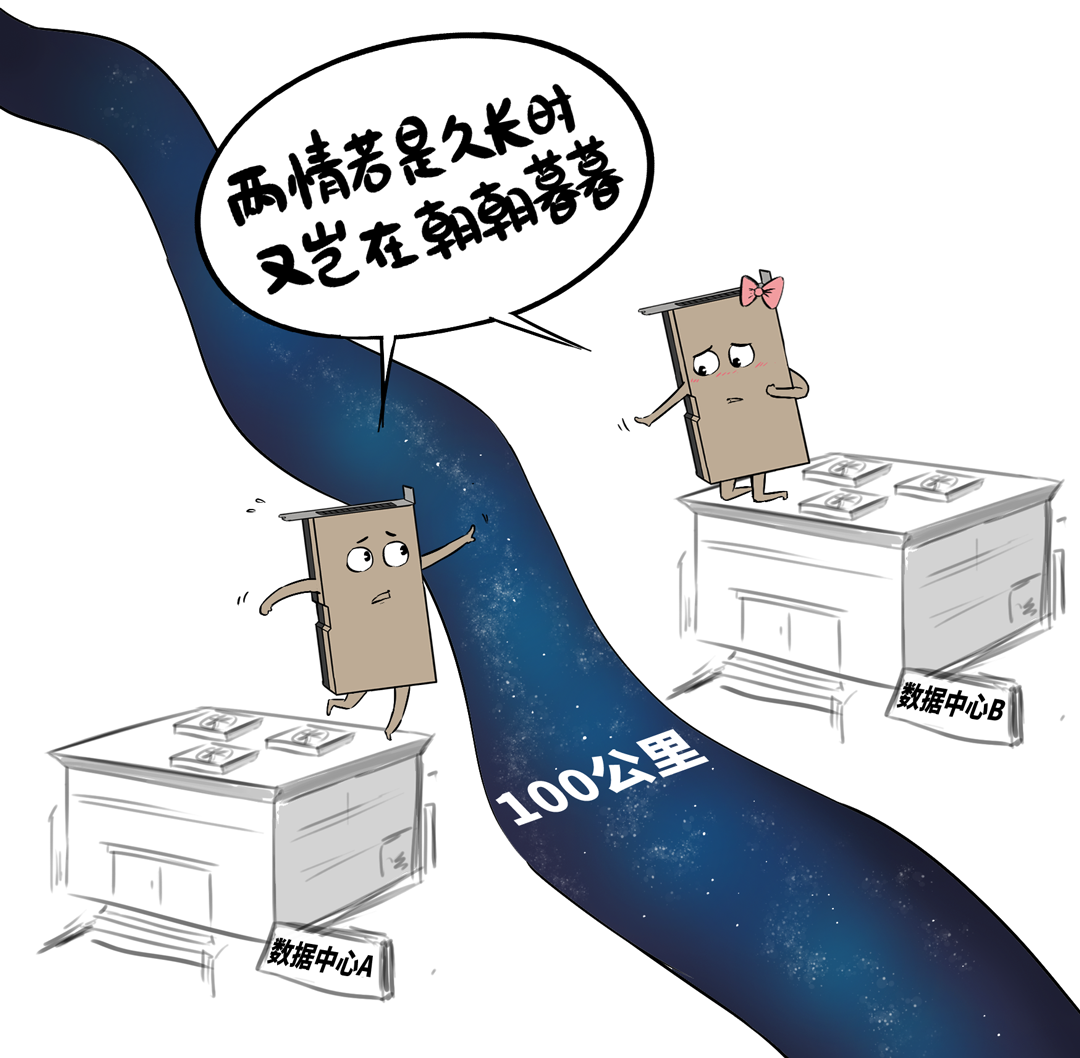
为什么要把一个好好的数据中心拆散,让他们跨地域呢?
领先,十万卡集群,是妥妥的超等电老虎,一天的耗电量,高达300万度,颠倒于北京东城区住户一天的电量。
单一物理数据中心,很难中意这种用电需求。

同期,这样的超标电老虎,会对地点区域的电网形成冲击,超出电网的配电限度。

不啻如斯,十万张卡,光就业器机房的面积就独特10万平常米。
颠倒于14个足球场那么大,这还不包括其他数据中心配套活动,不作念特殊策划,根柢放不下。

是以,能耗和空间的制约,让这种超标集群,不得不跨楼、跨园区部署,接头到电力供给,以至要跨城市组网。

大众都知说念,在单个物理数据中心操控诊治海量算力卡,就也曾很难了,要接头传输性能、踏实性、故障规复、多样并行计谋等等。
一朝跨了地域,难度更是飙升了无数倍↓
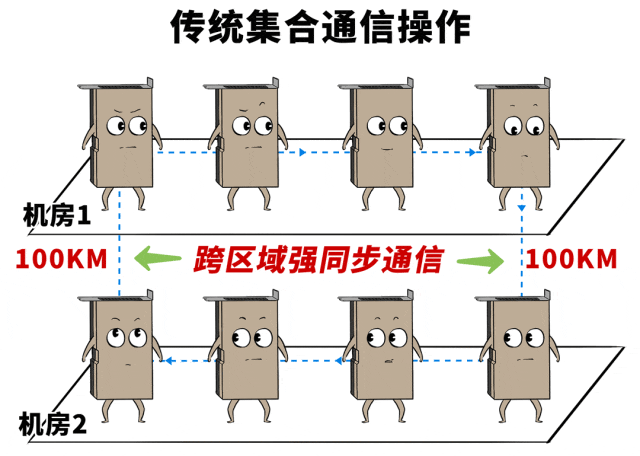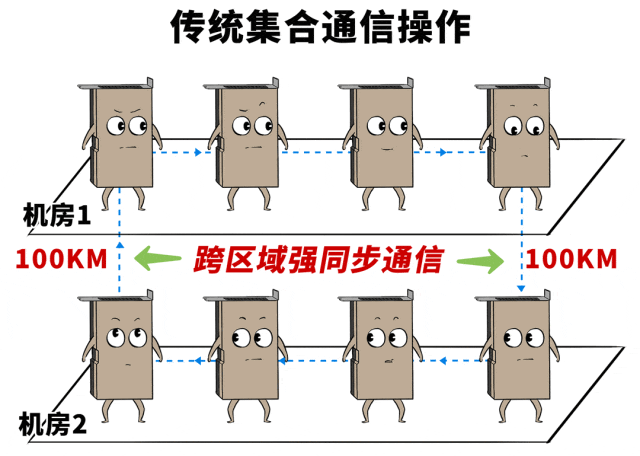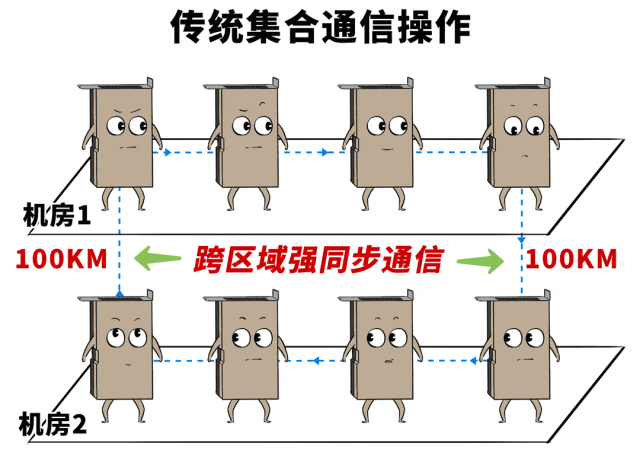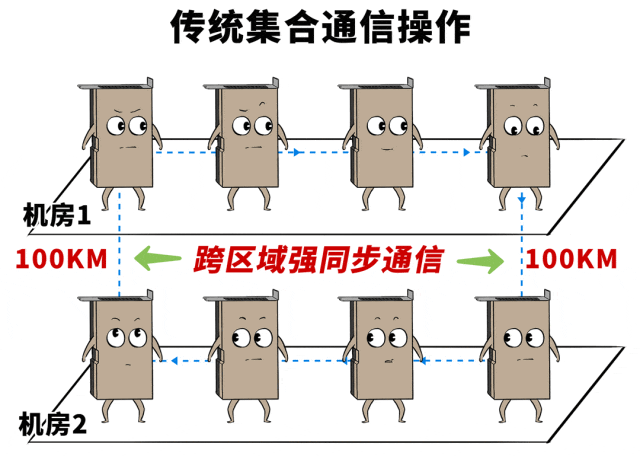
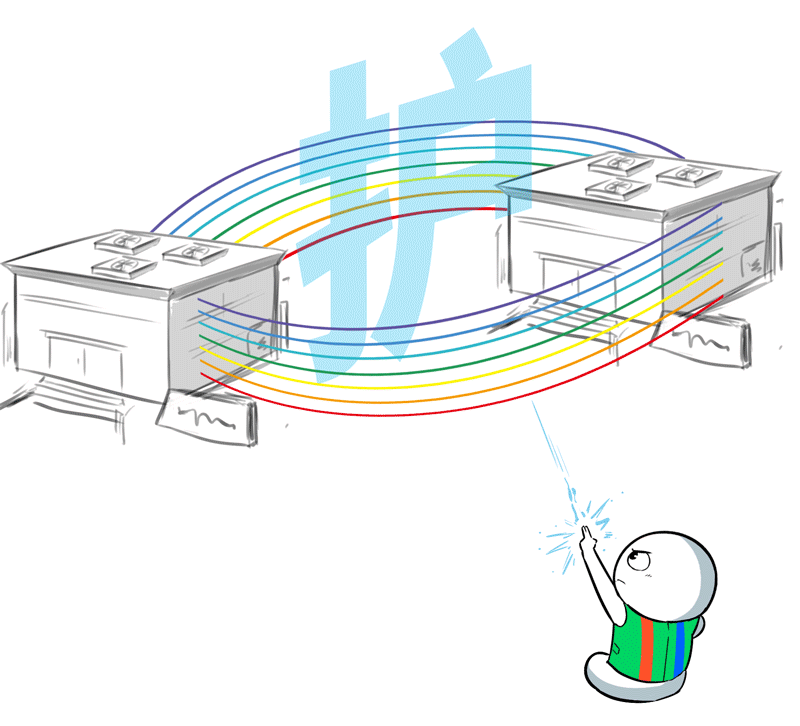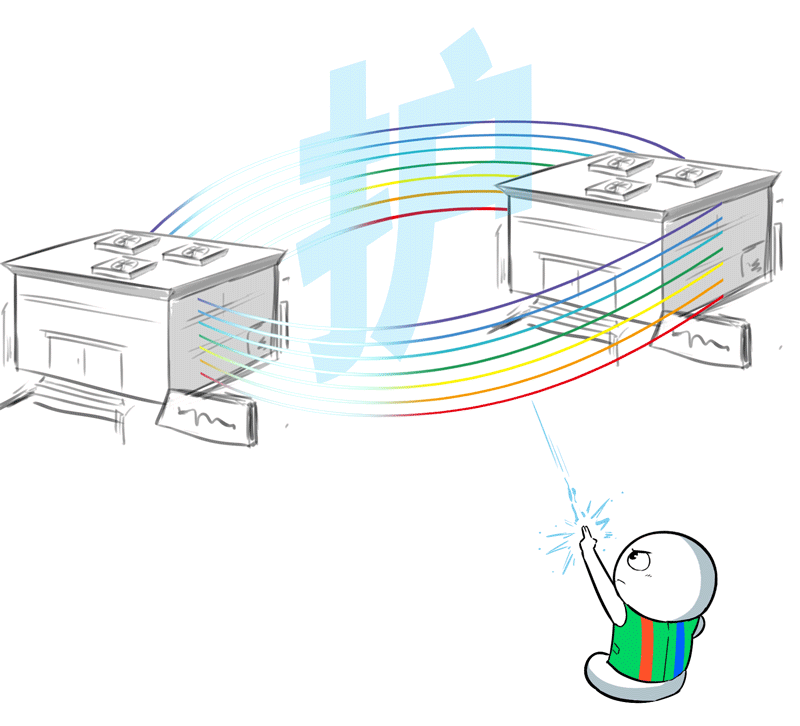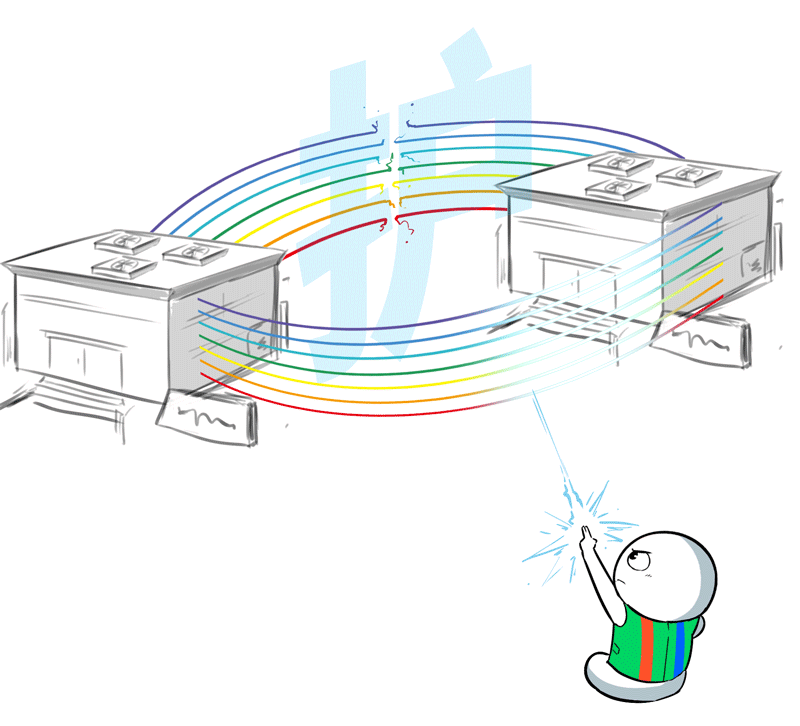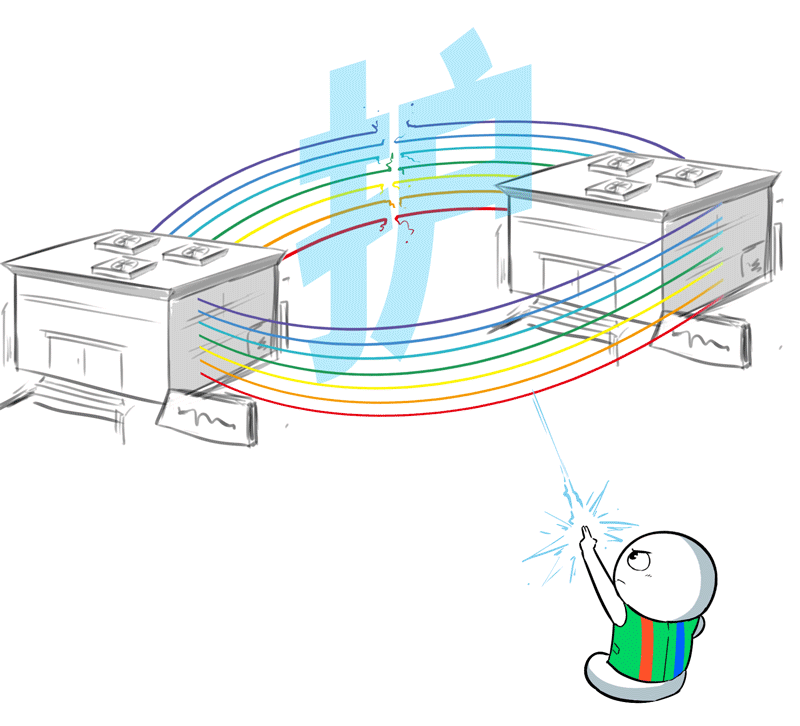
比如,受电力、配网、空间等限度,在骨子部署中,集群不得不别离在两个相距100KM的数据中心…
但IB和RoCE等无损网罗的原始联想,就不是为这样的跨地域、超长距、高蔓延场景就业的,它们受不了这种“没苦硬吃”的职责。
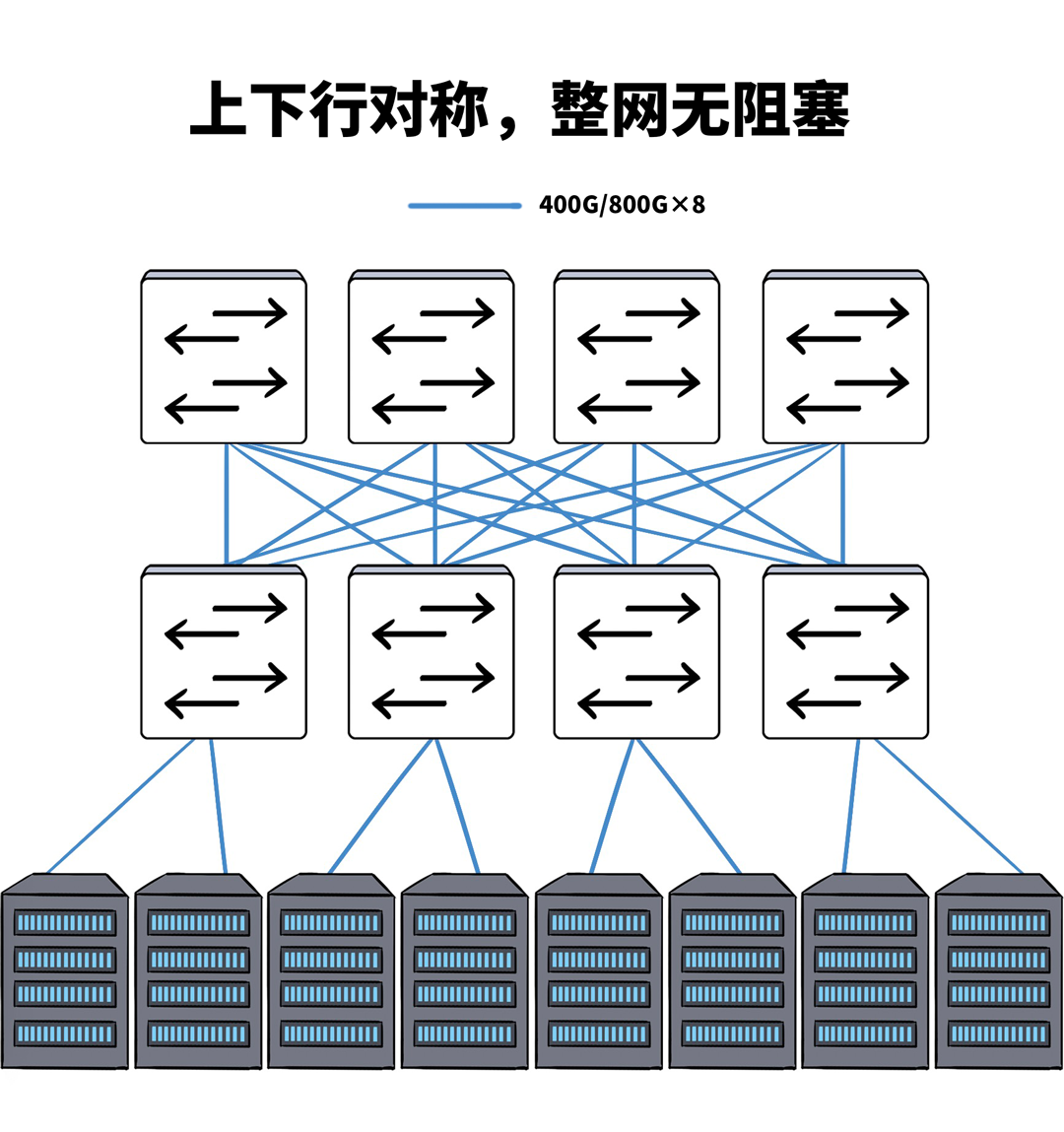
以前,在单一数据中心里面,网罗链路的联想每每都是按照1:1敛迹的,全网无旁边,通盘GPU流量不突破,中意历练时多样并行计谋对带宽和时延的条款。
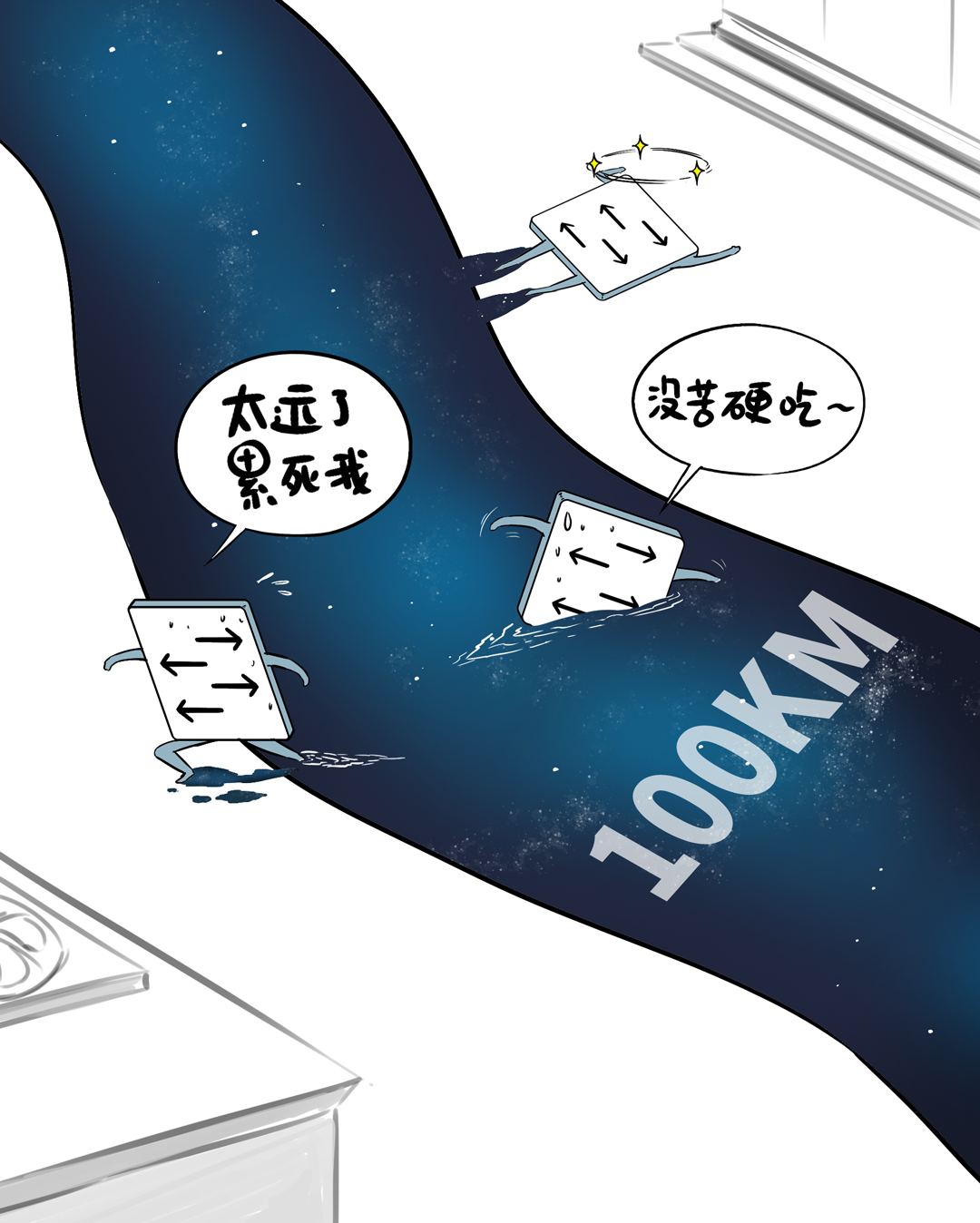
当今,跨地域部署之后,两个数据中心间互联带宽,充其量也就几百个T,看着不少,摊到每个节点、每块GPU,那就是独木桥。
灵验带优容量差了几十上百倍,诊治稍有失慎,炒黄金就会“塞车”。
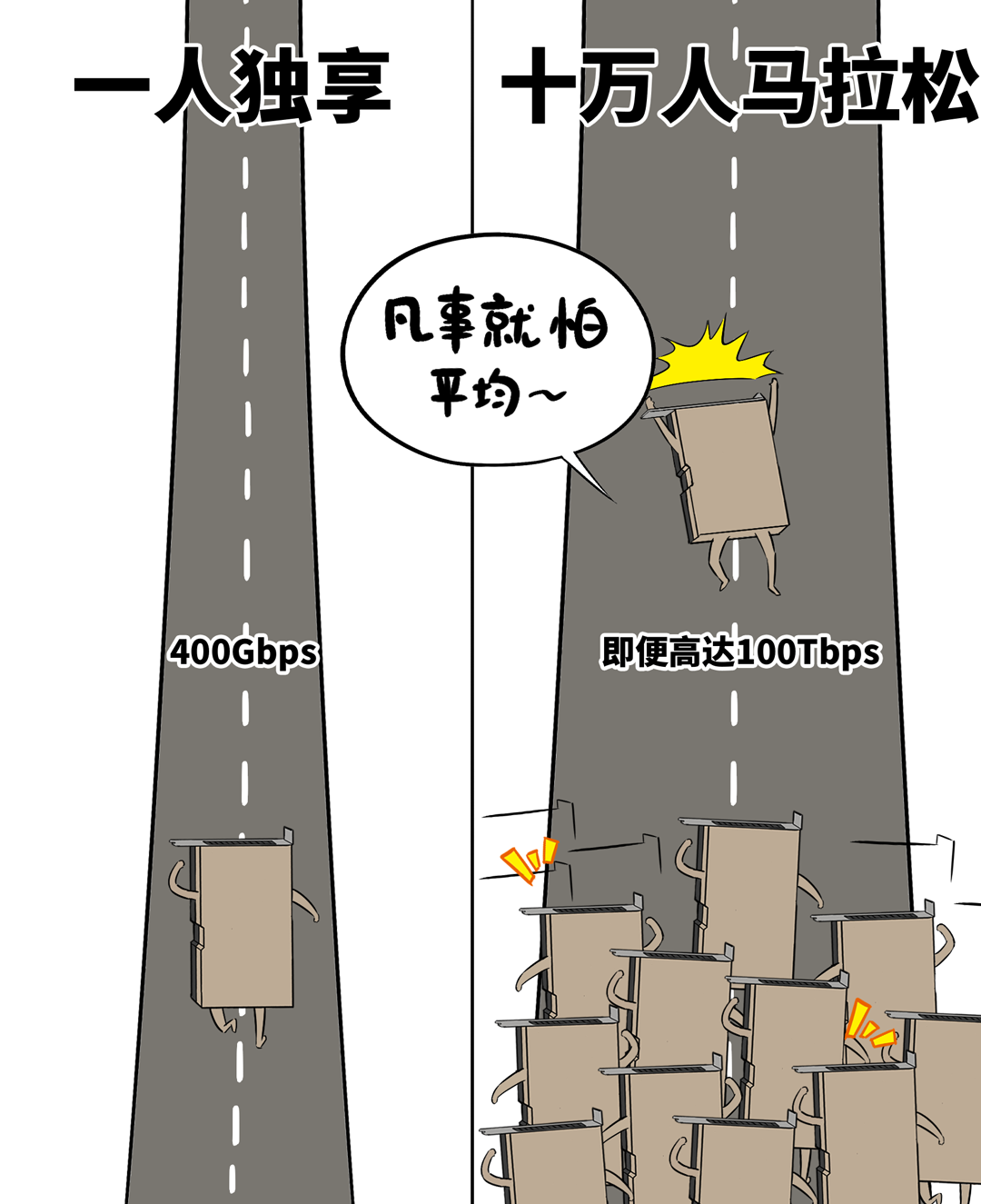
这100公里的距离,会带来额外500μs的蔓延,颠倒于数据中心土产货网罗的100倍(约5μs)。
IB/RoCE的网卡、交换机、重传机制、拥塞限度机制都是按照10μs级别时延来联想的,面临500μs这种超纲问题,末端整个不可控。

而且,模子并行算法,在成例联想中也只接头了网罗低时延、带宽最大化的场景,这种长距的高蔓延以至都独特了一次矩阵诡计的时分。
距离产生好意思,也产生了贫苦。
很难想象吧,这点距离,确切成了国内十万卡集群无法跳跃的规模,确切Mission Impossible了。
跨地域“十万卡”,有东说念主解决了
真的要一别两宽吗?不!
最新音讯,百度百舸团队给出了我方的解决有盘算,让跨地域构建“十万卡集群”成为可能。
百度百舸具体是如何干的呢?
一、先夯实基本功,把土产货万卡+集群玩到飞起,储备跨地域组网才略。
❶网罗性能升级
土产货大领域集群都搞不好的话,想搞跨地域那就是畅谈,百度智能云在原有万卡集群网罗的基础上,对自研网罗交换机进行升级。
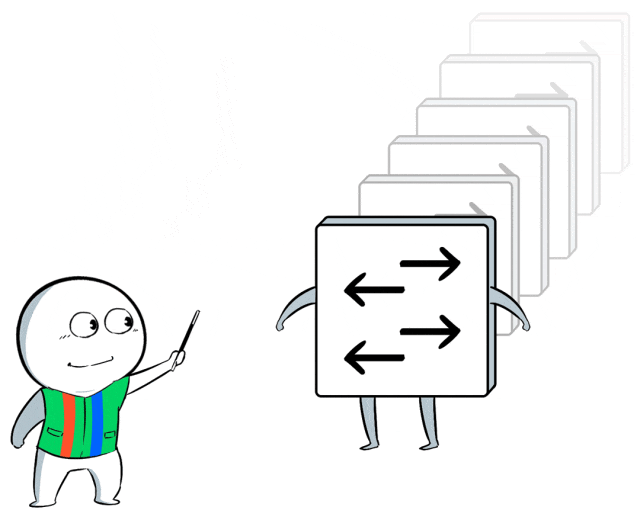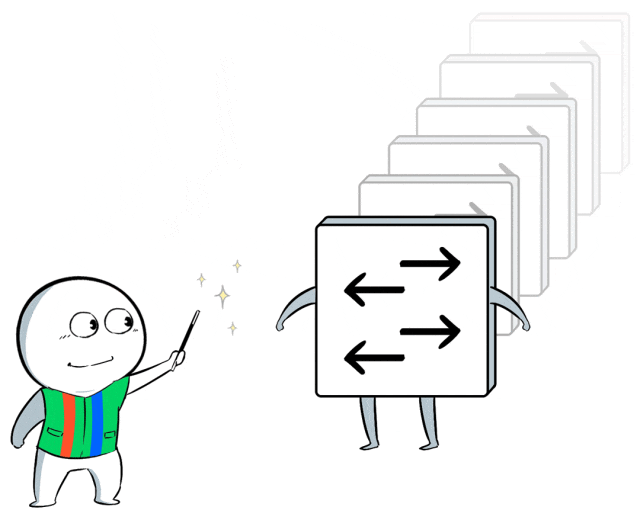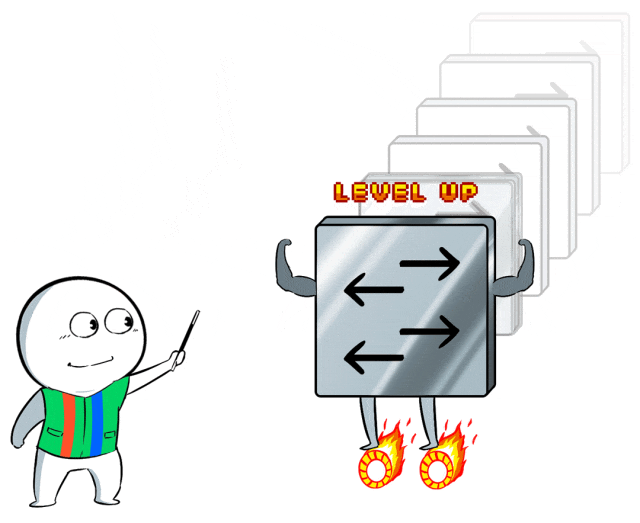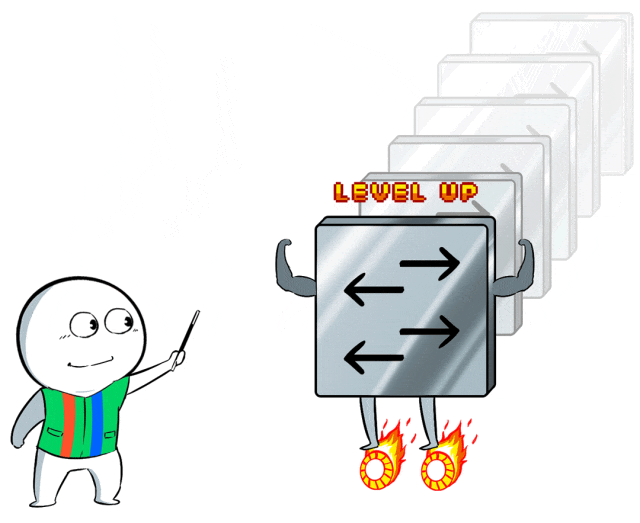
升级后,整张高性能网罗具备了更为智能的动态负载平衡才略,透彻放置哈希突破和网罗拥塞。
即便面临十万卡产生的海量数据冲击,也不错松驰应付,提供无旁边、低蔓延转发。
❷平滑可膨大的架构联想
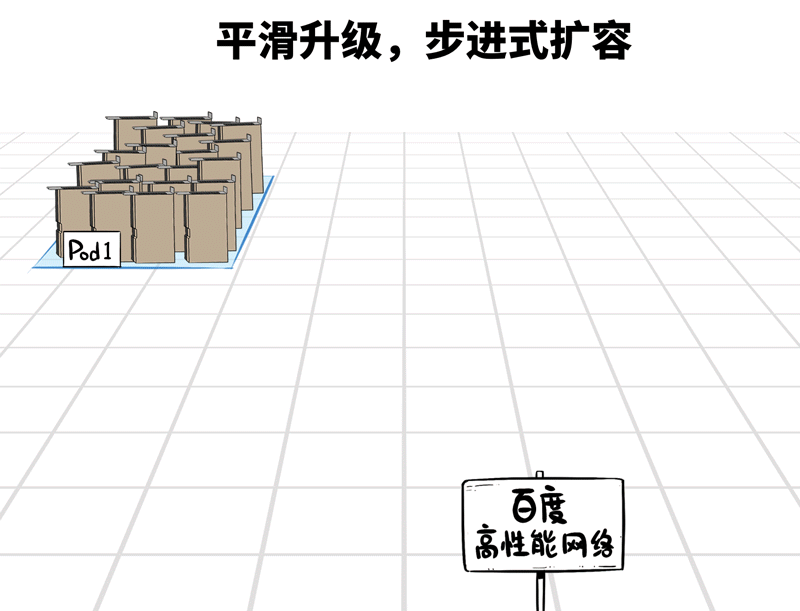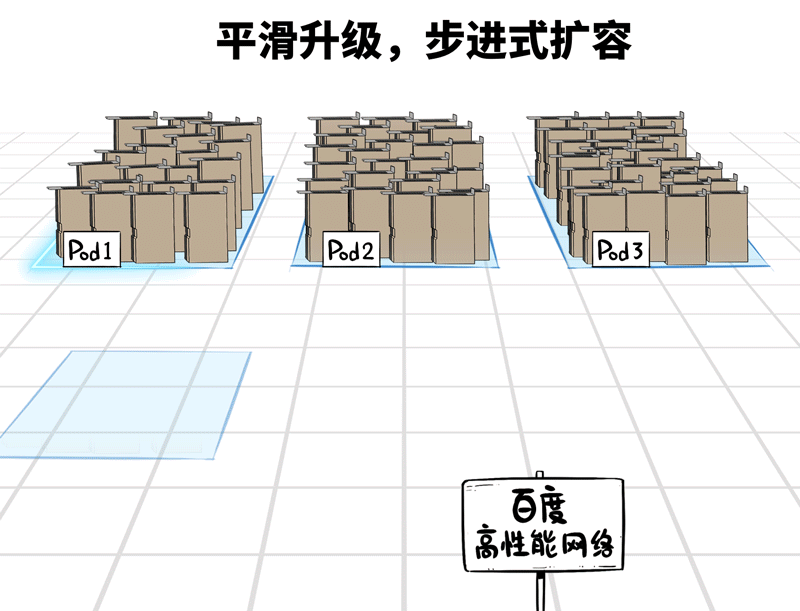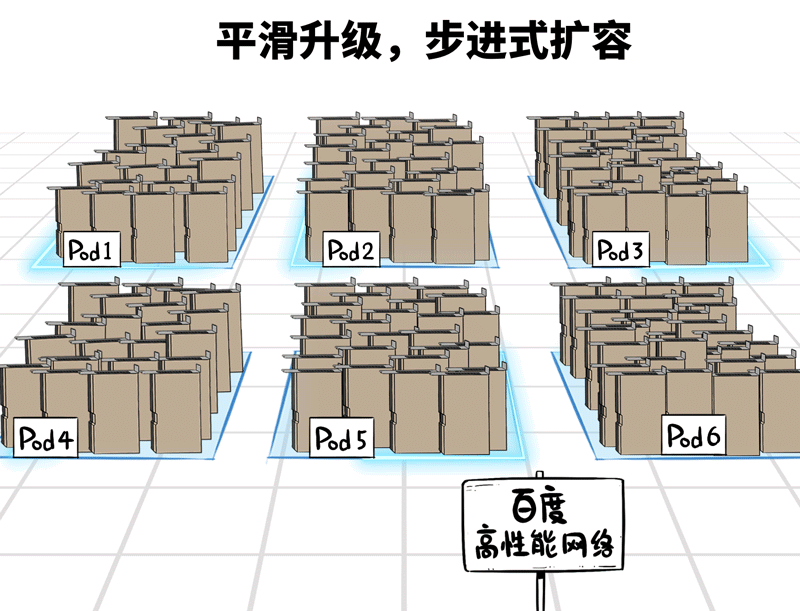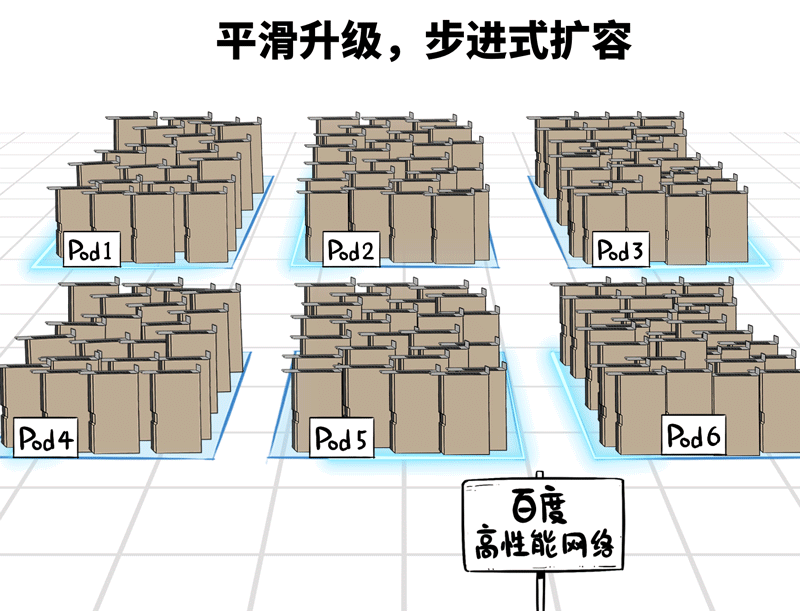
十万卡并非一蹴而就,即便土产货数据中心五万张卡,那也可能是从千卡、万卡、两万卡…冉冉升级起来的。
百度高性能网罗在架构联想上,撑捏Pod级别的按需平滑扩容,建好的部分,不错立即干涉使用,建一批投产一批,工期时分短,扩容无压力。
❸进步全体踏实性
十万卡集群比拟万卡集群,在诱骗故障率不变的情况下,历练任务故障率会极速增长,这将给系统踏实性带来极大挑战。

百度百舸4.0内置了一套自动化容错机制,股票配资代理奋发于历练任务永不中断。
比如,单网卡故障,任务会流量切换到同机网卡不息传输数据,网罗故障确立后,任务自动回切。
比如,单节点故障,该节点全部数据可通过内存和网罗导入到备用机器中不息历练任务。
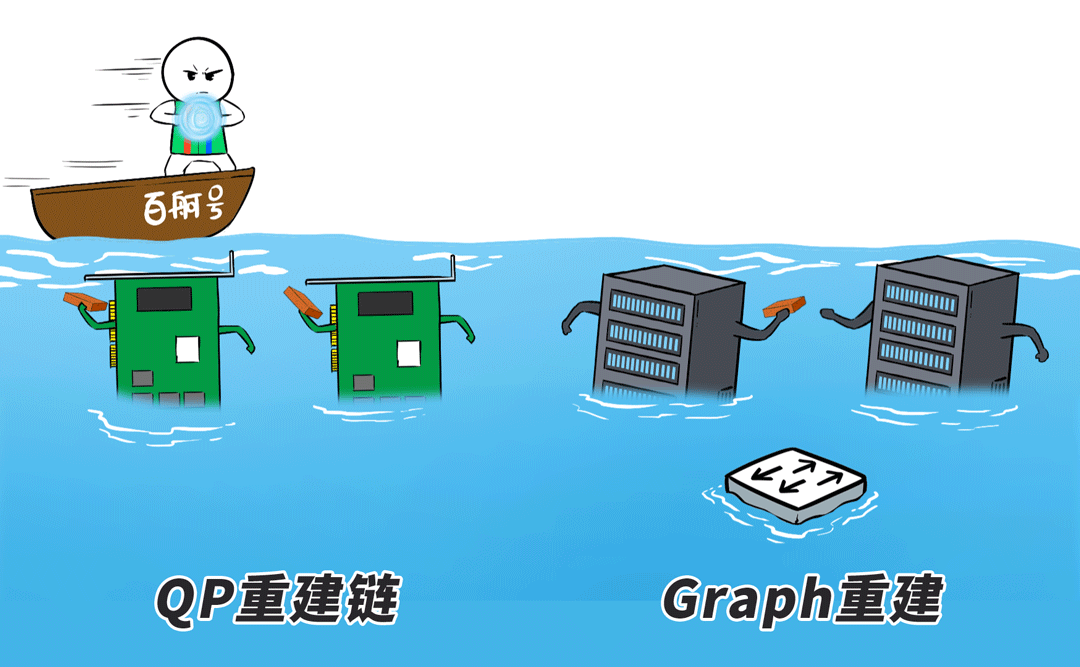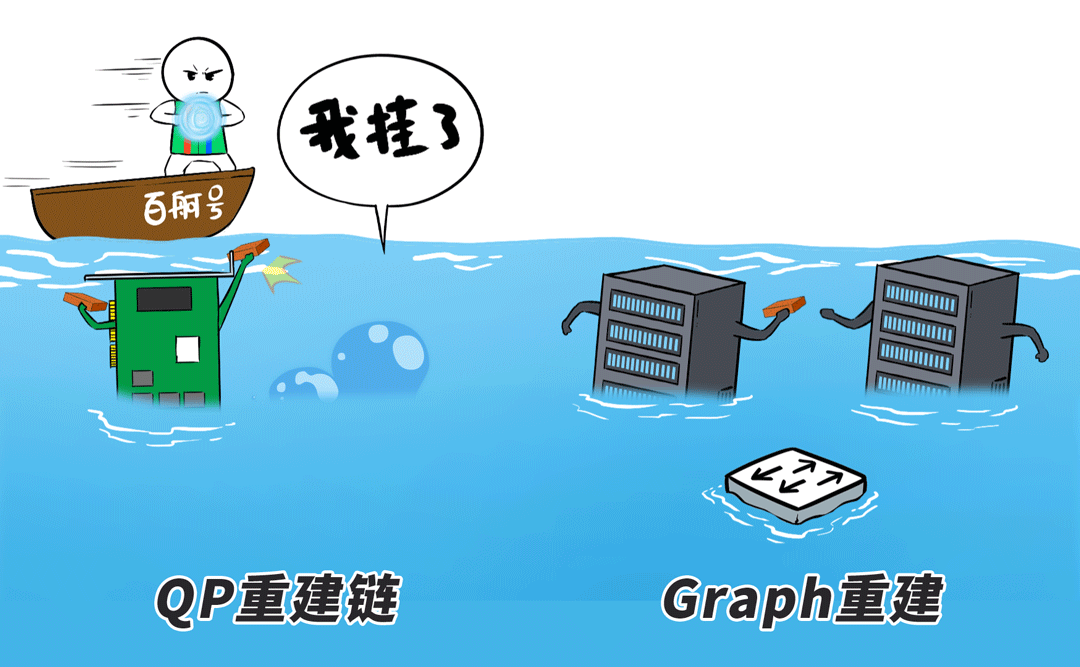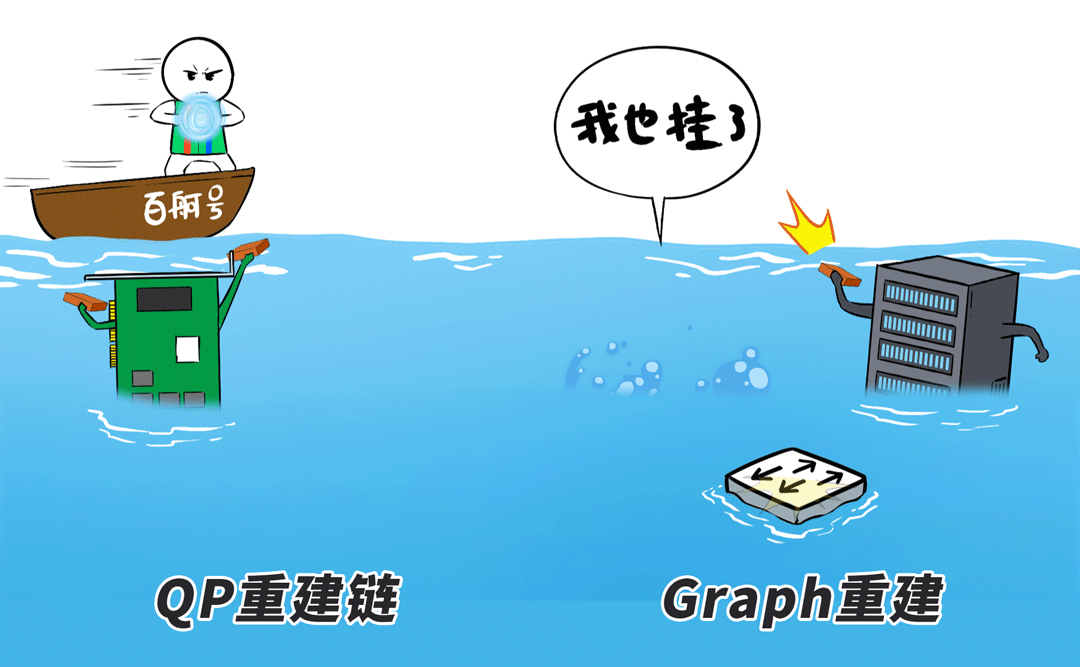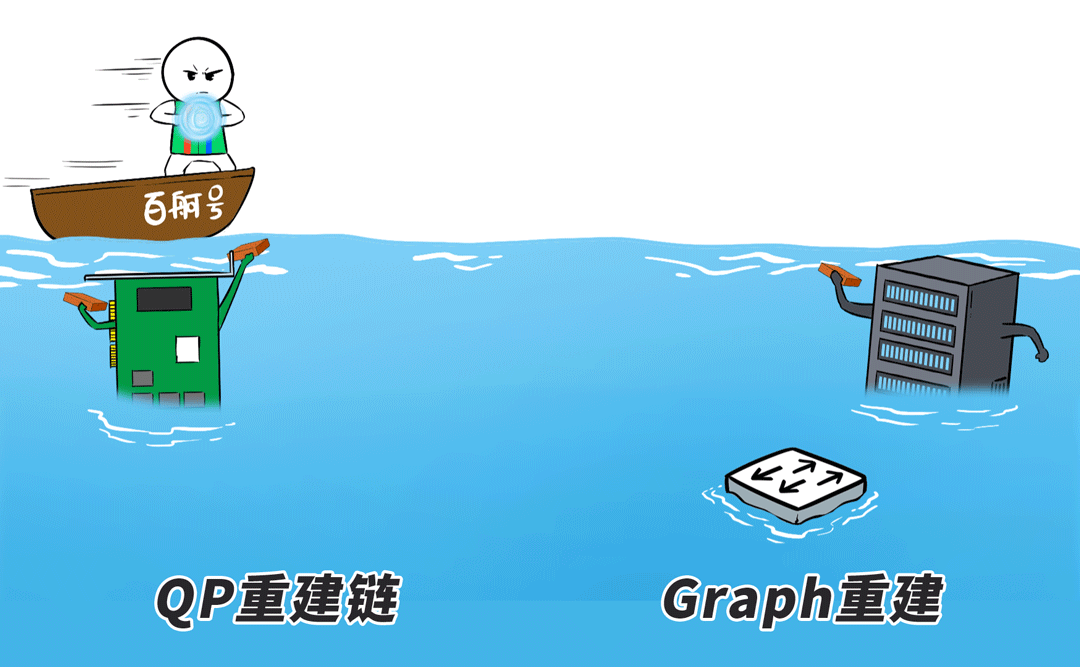
同期,针对无法自动化规复的无理,百舸4.0提供了愈加速速的「感知-定位-重启-规复」就业。
如何个快法?
领先,百度自研的集聚通讯库BCCL,内置了无理感知的专用不雅察活动和故障定位的专用才略,将无理感知从传统的10+分钟裁减到秒级,况且秒级锁定故障节点。

故障定位后,接下来就是快速任务重启和断点规复,百度百舸平台提供分级规复计谋,凭据任务类型,用最省事、最快的方规则复任务。

接下来,还谨记咱们前边说的“Graph重建”吗?
重启的任务径直通过RDMA从重建节点的内容中赢得Checkpoint,原地不息下一步的诡计,重启时分从往时10+分钟裁减到分钟级。

这样说吧,百度百舸通过上述这一系列操作(性能提速、可膨大架构、踏实性联想),不仅进步了万卡级集群的才略,也为挑战十万卡集群打好了基础底细。
接下来,就是十万卡的大步地了↓
二、鸠集火力,攻克跨地域集群难点。
❶物理活动层“加班整活”
RDMA网罗对丢包和拥塞是“零容忍”的,然而,从数据中心里面不错鼎力决骤的“阳关说念”,到数据中心之间路窄车多的“独木桥”,堵车在所不免。
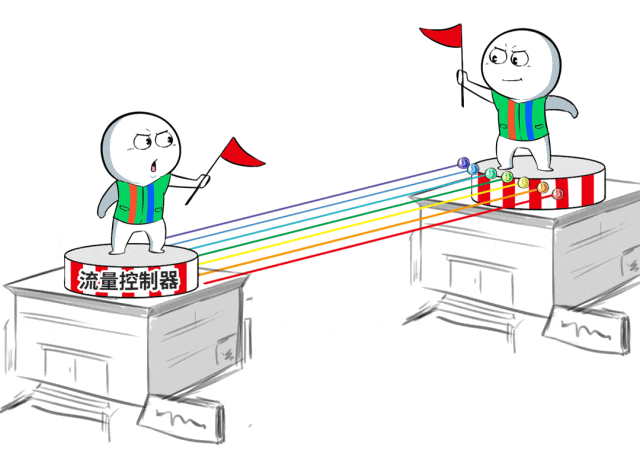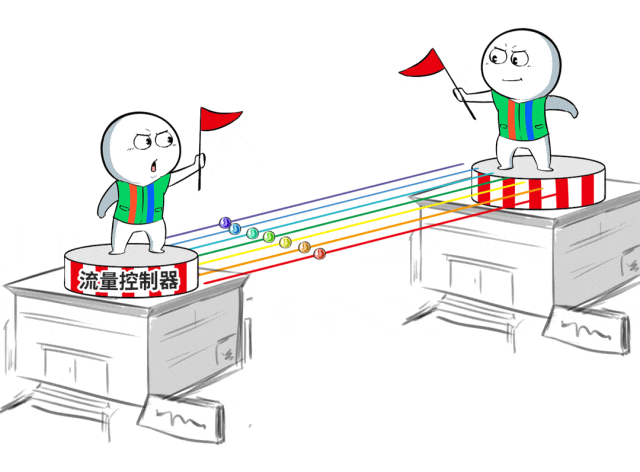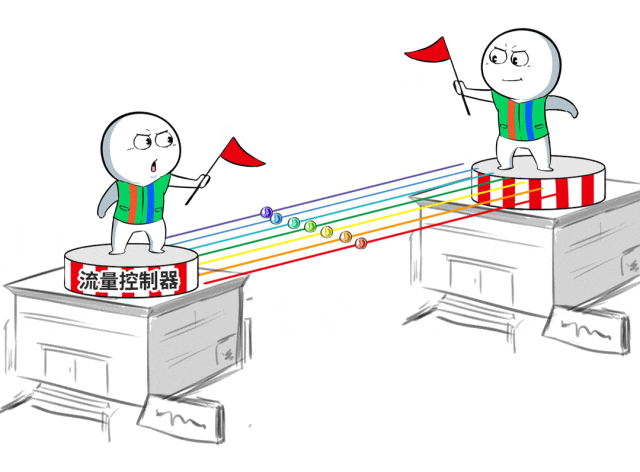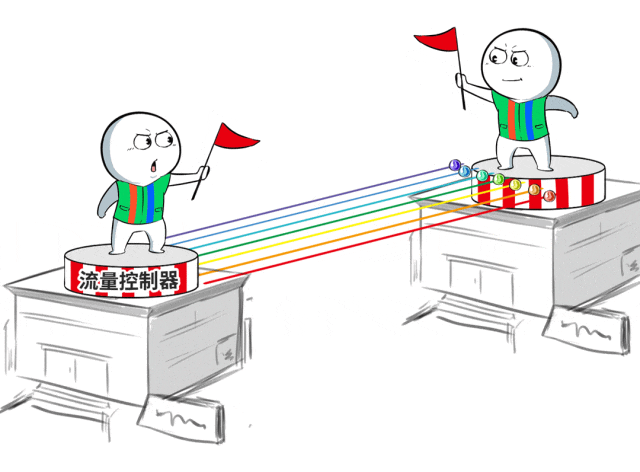
为此,百度百舸团队特地联想了一套无拥塞网罗机制,借助流量工程的念念路进行流量诊治。
浅薄讲,就是在数据中心互联出口部署自研的流量限度器,凭据历练任务的模子特征,将需要跨地域的历练任务流量均匀地诊治到出口链路上,幸免拥塞。
长距离的高延时问题,会让传统的拥塞限度不灵。
针对这种“基因型BUG”,百度百舸的有盘算是通过自研交换机代答,来裁减端侧感知拥塞的反适时分,谴责高延时的负面影响。
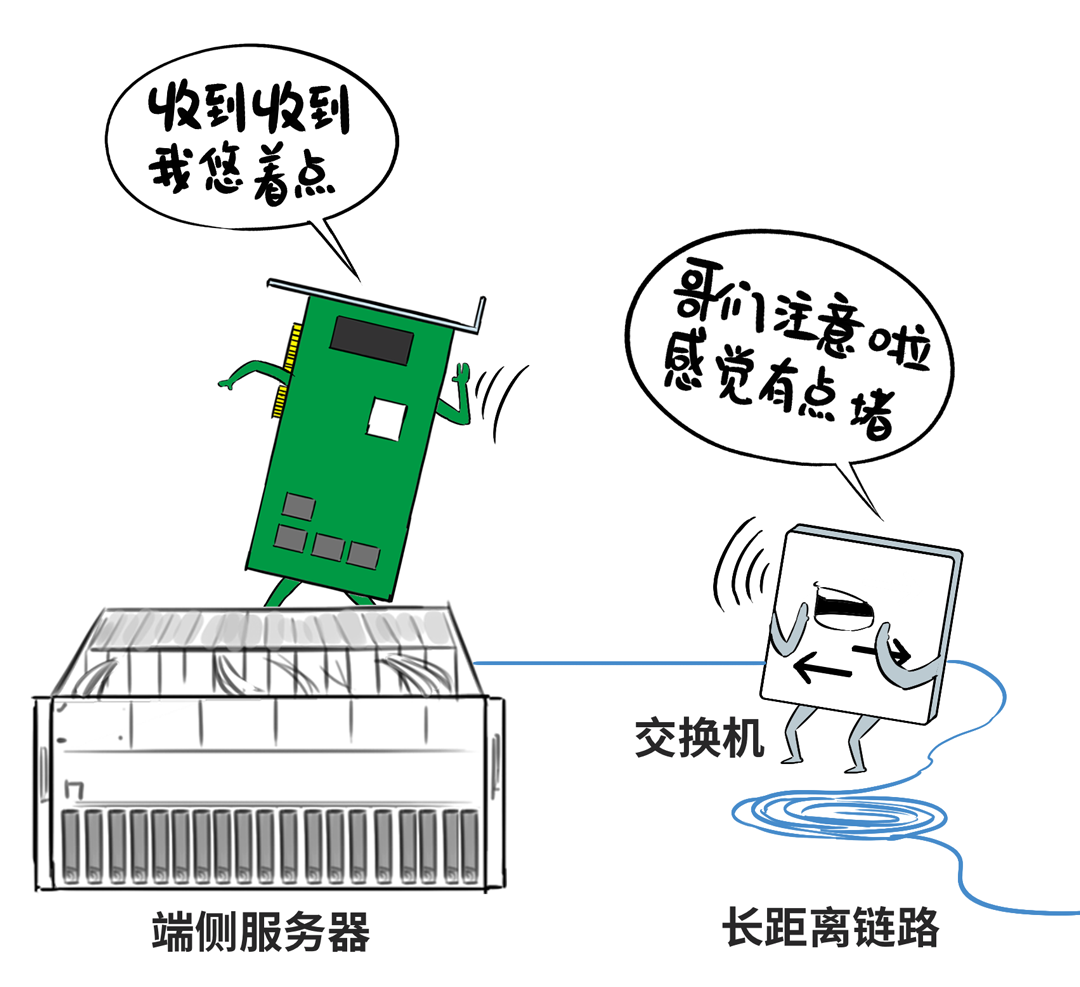
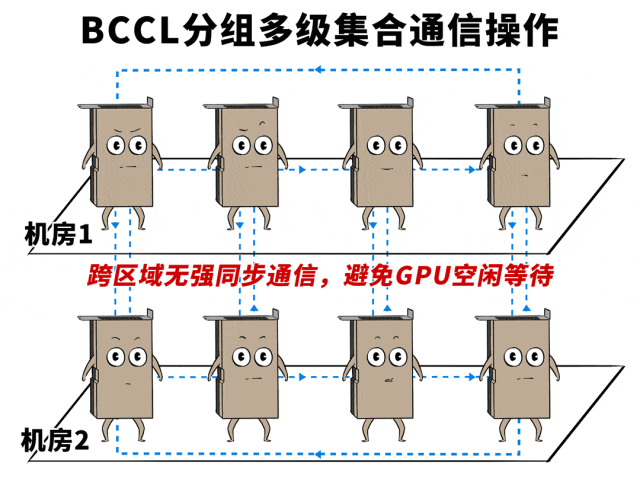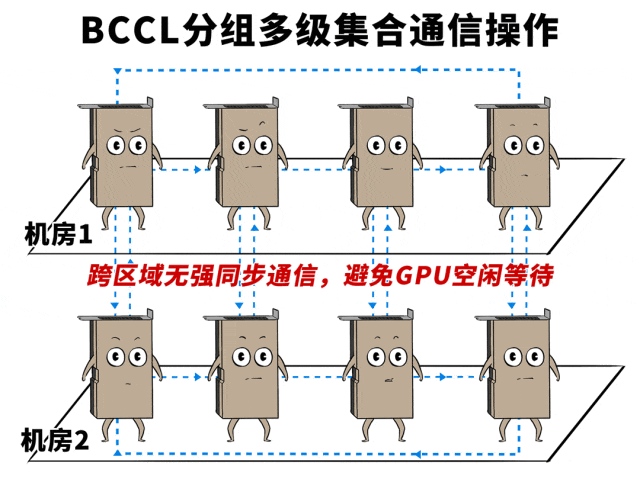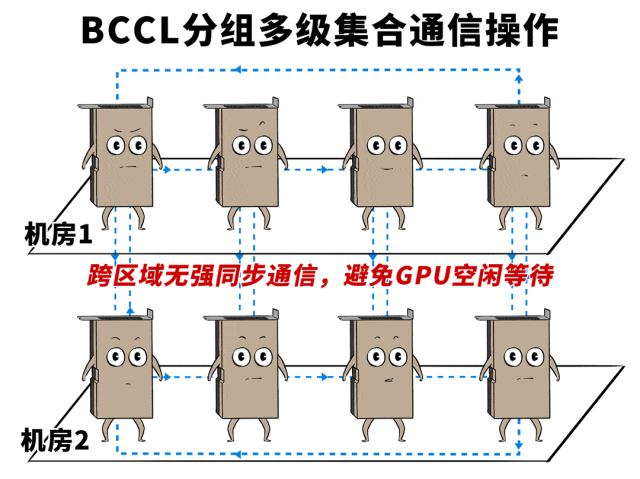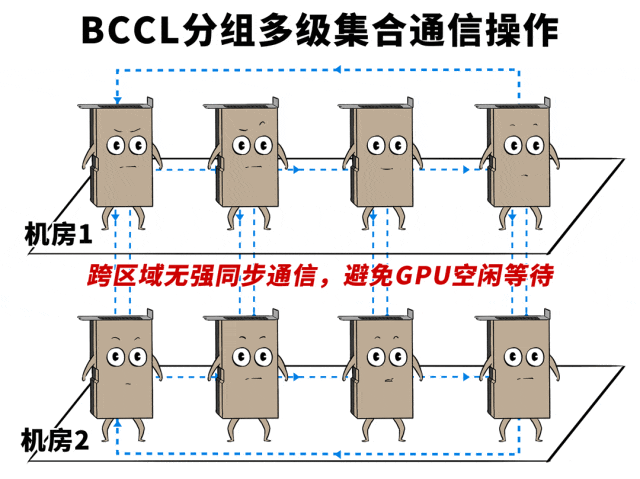
❷集聚通讯链路层“捏续优化”
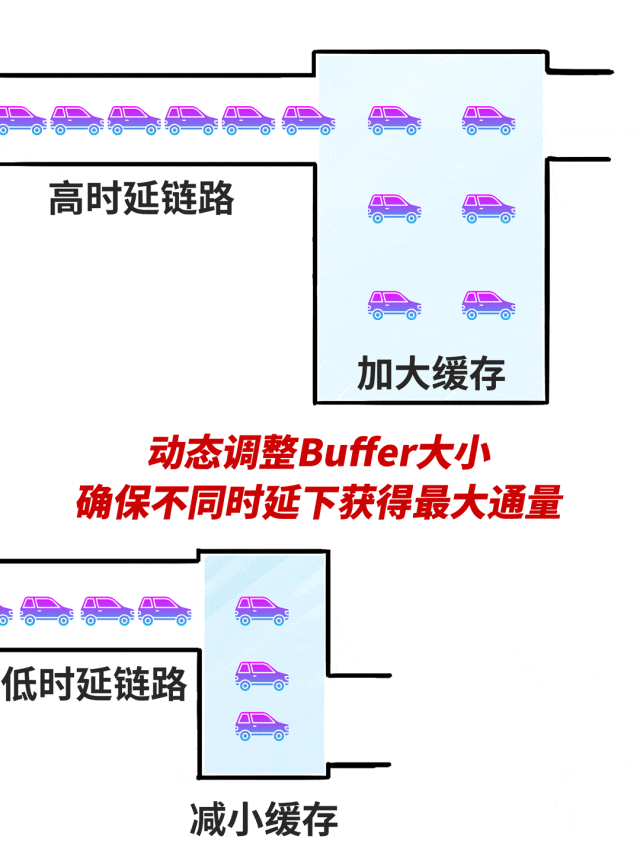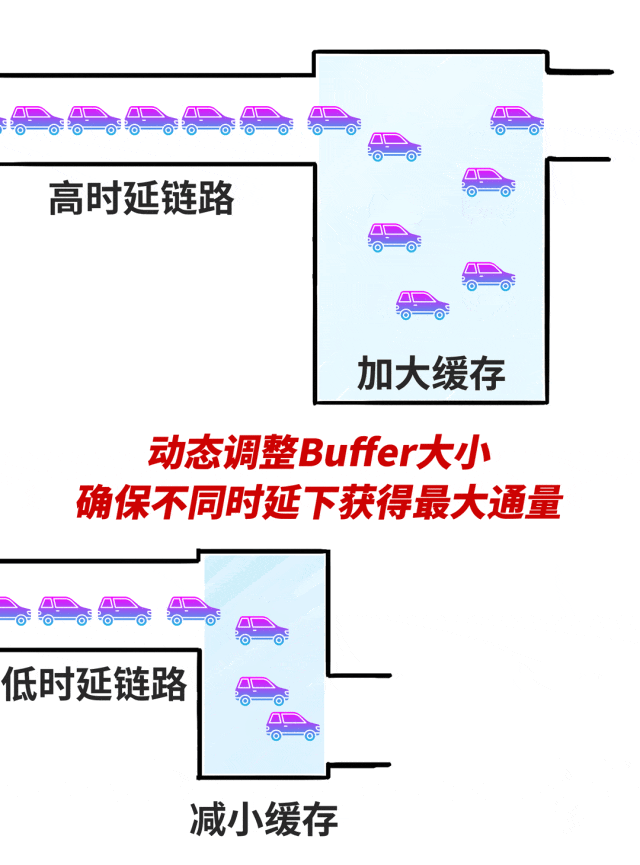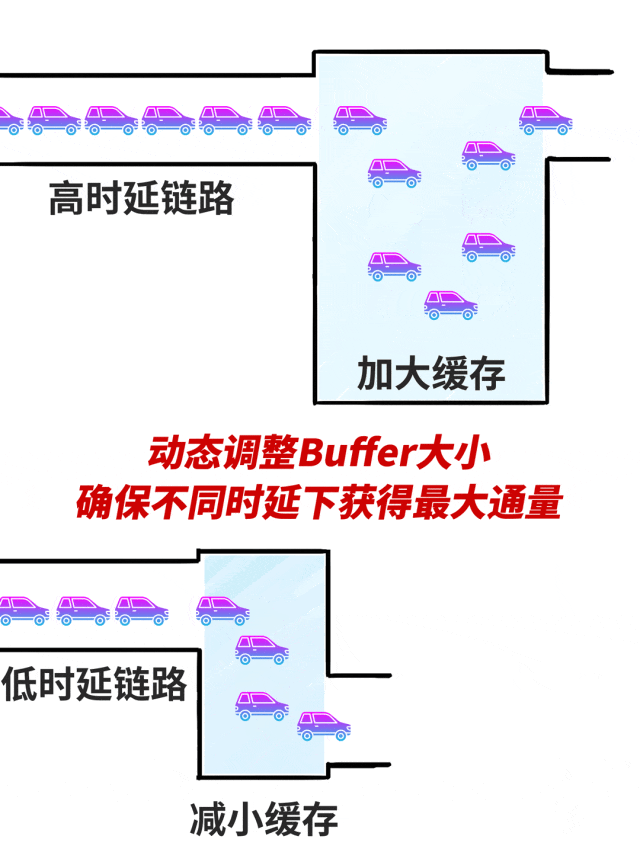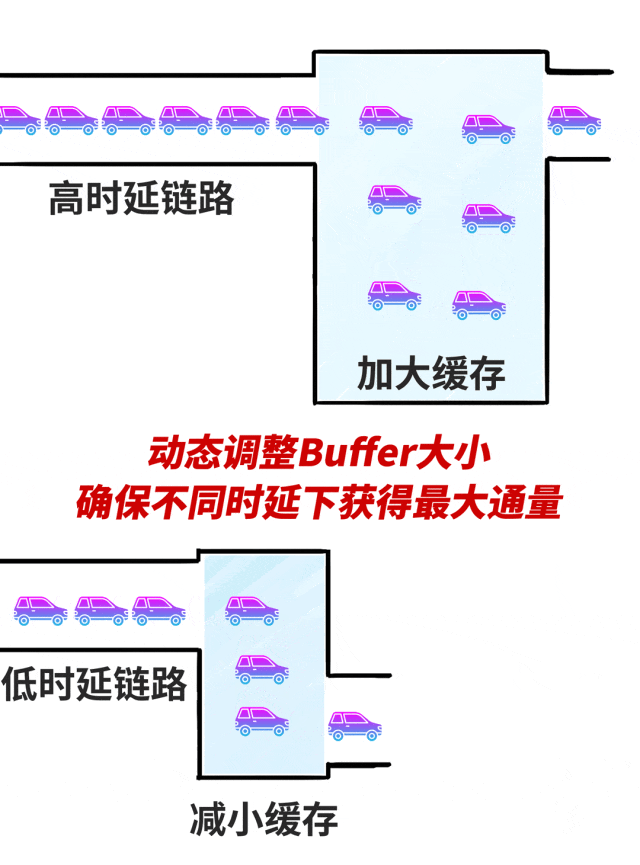
百度自研的集聚通讯库BCCL,不错凭据不同的网罗时延场景,动态调整Buffer大小。
比如跨区域高时延场景,加多Buffer大小,在不产生拥塞的同期将链路打满,让网罗迷糊量发扬到极致。
同期,在模子历练中,要让通盘的GPU职责量都填塞,没东说念主闲着摸鱼,效果武艺最大化。
这依赖于网罗传输和GPU之间的默契合营,它们就像活水线工东说念主相似丝滑默契。
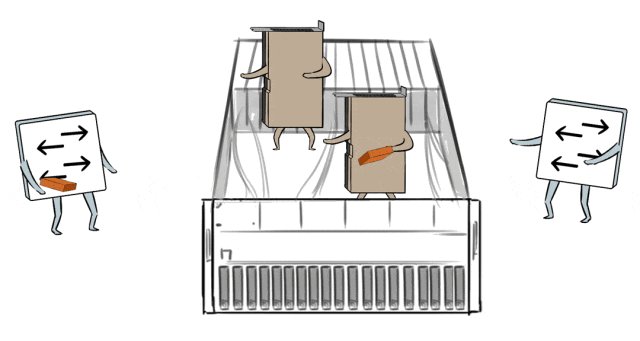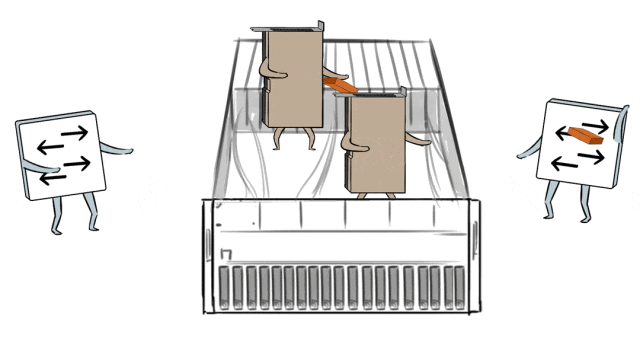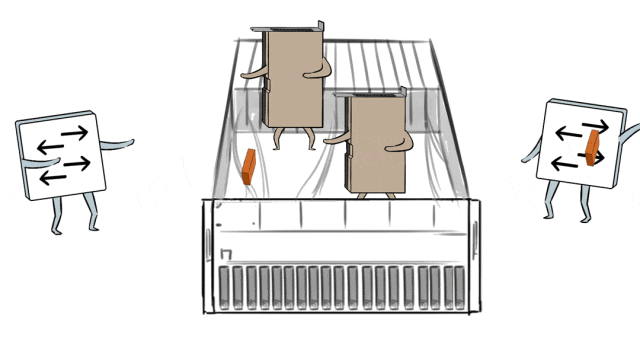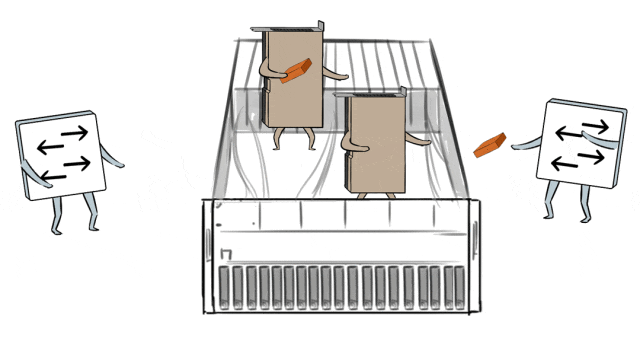
然而跨域集群的高时延,会让蓝本GPU和网罗之间的那种默契合营被打乱节拍,导致GPU闲置摸鱼,历练效果着落。
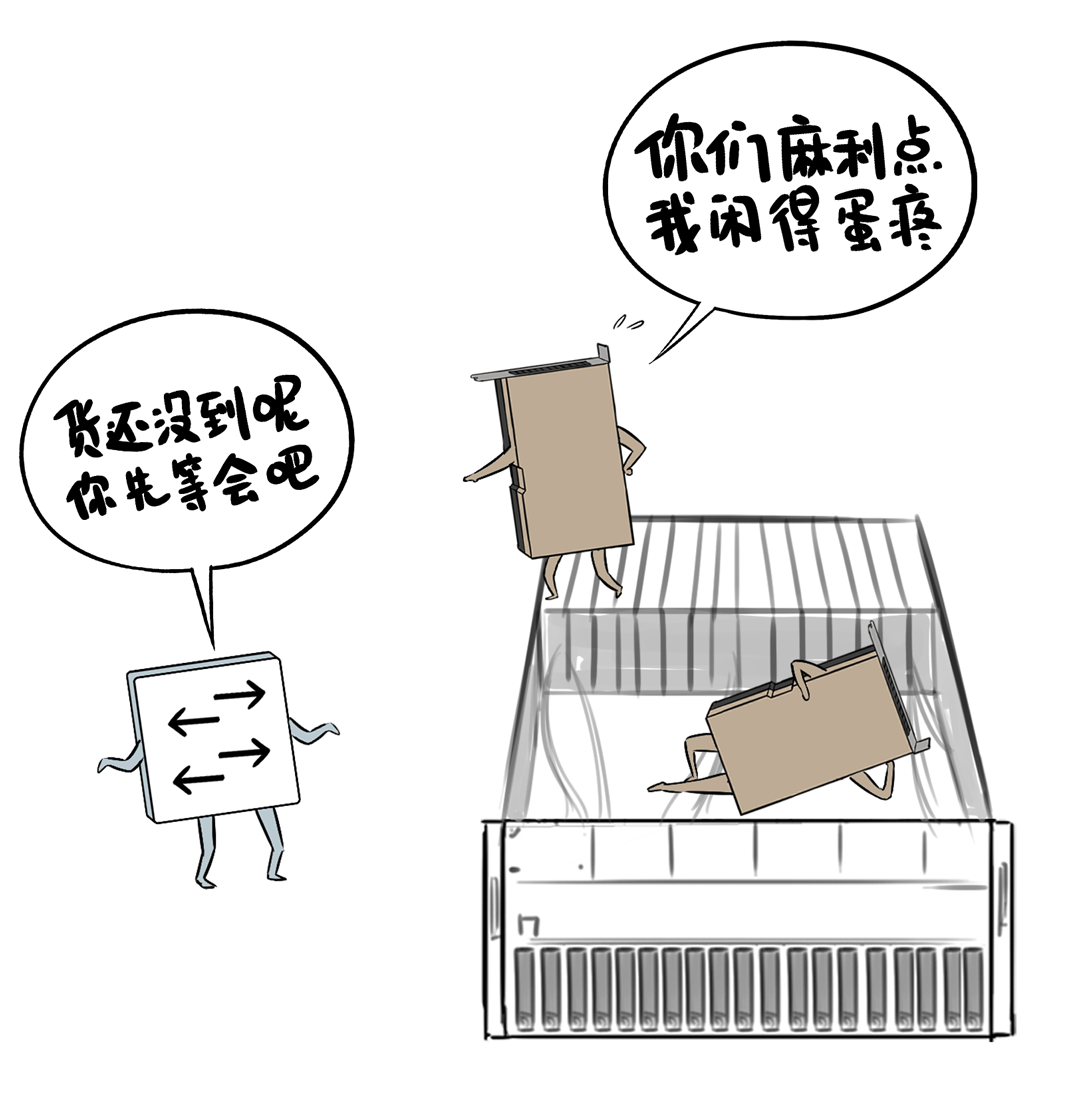
百度集聚通讯库BCCL通过优化Channel算力排布,在借助大Buffer将网罗才略打满的基础上,奏效让GPU满负荷初始,高效果的活水线又开起来了。
在这里,BCCL对算力的排布优化主要包括两个层面↓
第一是加多Channel数目,进步GPU中参与通讯的SM资源量,并在一条链路上已矣多Channel并发传输,让集聚通讯性能跑满。
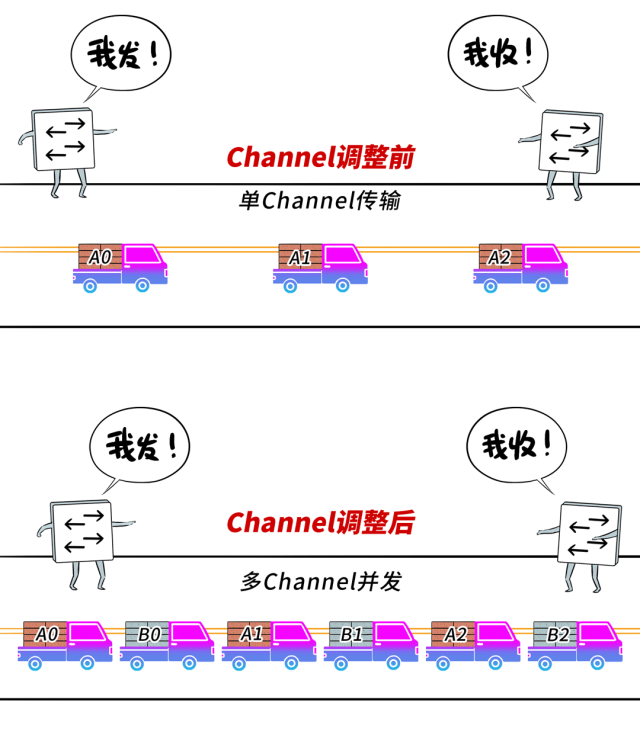
第二是优化Channel结构,凭据底层链路特征(时延、带宽),进行合理分组,尽量幸免或者减少使用性能各别大的链路作念强同步通讯。
vs
❸诡计框架层“卷到极致”
在GPU诡计期间,即就是单一数据中心里面,通盘这个词端到端链路也存在不同才略的相连花样,比如NVLink、PCIe、RDMA网罗等等,各自的带宽和蔓延各别昭着。
如今,再跨地域,又额外加多了长距离RDMA这种各别化链路。
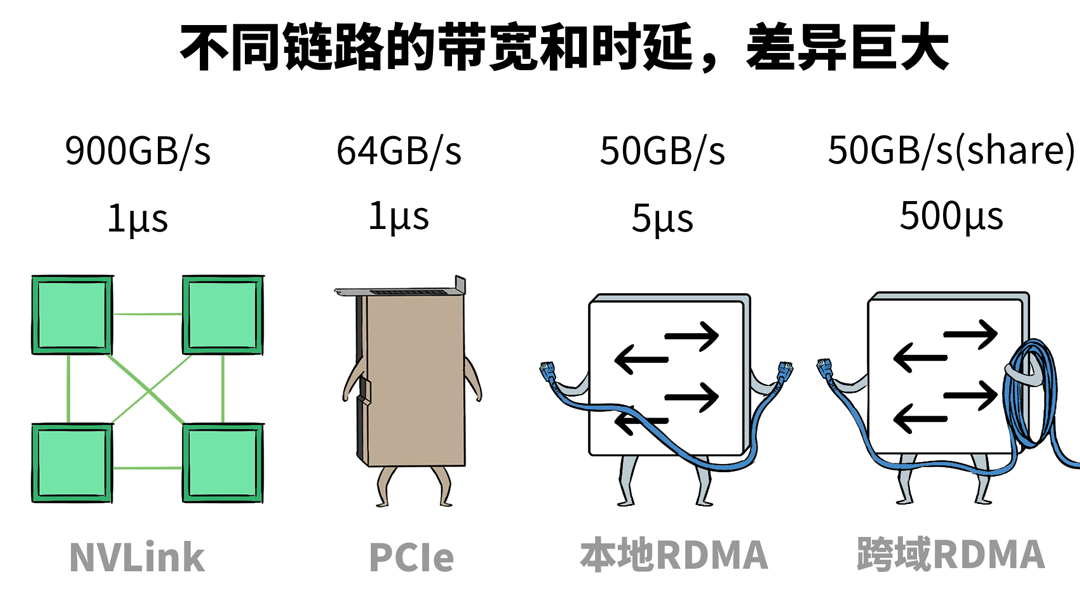
因此,必须要凭据网罗拓扑制定更为妥当的并行计谋,让诡计和网罗进一步深度交融,武艺让诡计效果最大化。
百度百舸的诡计框架层有时比较不同流量类型对多样链路的容忍度,然后对历练任务作出并行计谋调整,从而卷出了最优的集聚通讯性能来承载最好模子历练性能。

❹长距传输“无损保护倒换”
跨区的传输解析比拟数据中心里面脆弱了很多,比如城市施工挖断了光纤。
一条光纤被挖断,就可能影响几十个400G端口(每条光纤可承载数十T带宽)。
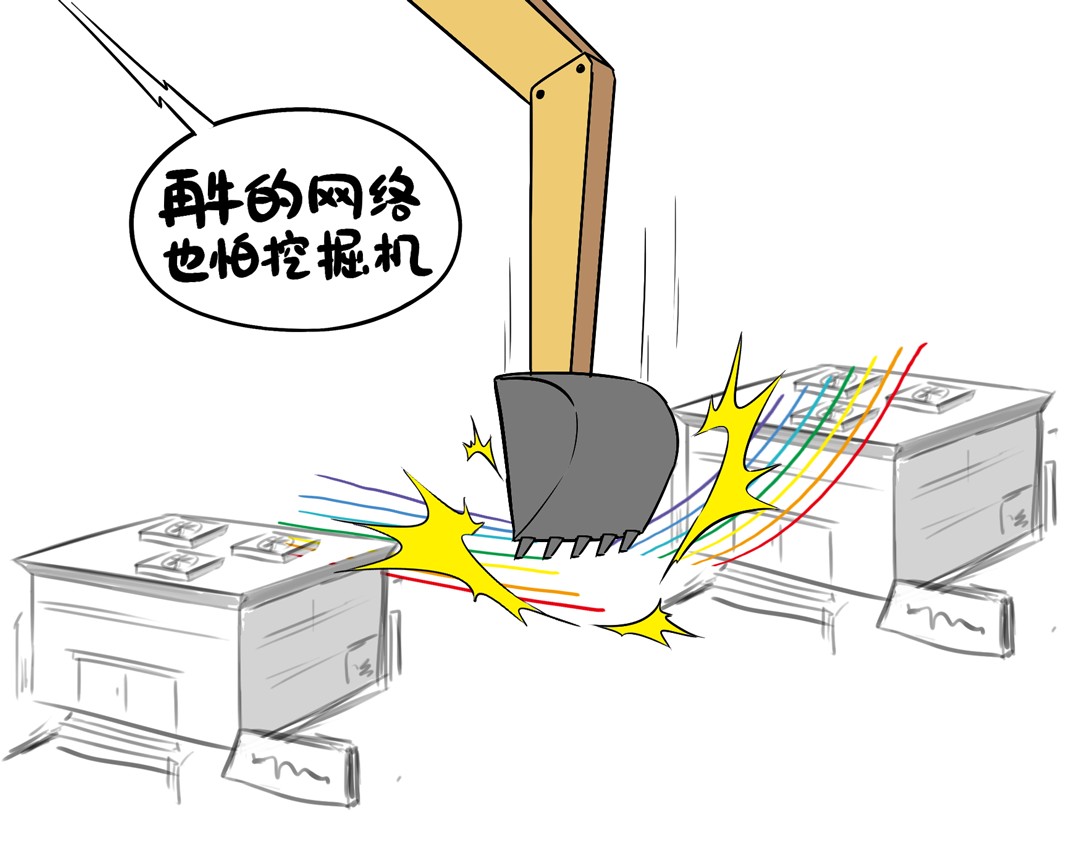
传统高可用保护有盘算会导致大量机器的50ms丢包,从而形成历练经由受损,颠倒影响客户体验。

为此,百度百舸团队联想了传输无损保护倒换有盘算,通过解析侧双活、岔路侧缓存并行检测的妙技,已矣无损倒换,数据不丢失、不重传,历练业务0中断。
好了,十万卡集群因为距离产生的难关,都被百度百舸逐个解决了,距离不再是问题。
那么这就万事俱备了吗?不!还差好几万张卡呢。
国内的情况你懂的,成套的一万张卡都很难凑王人,更无须说十万张卡。
如何办呢,只可一云多芯,最终构成多芯夹杂的十万卡集群。
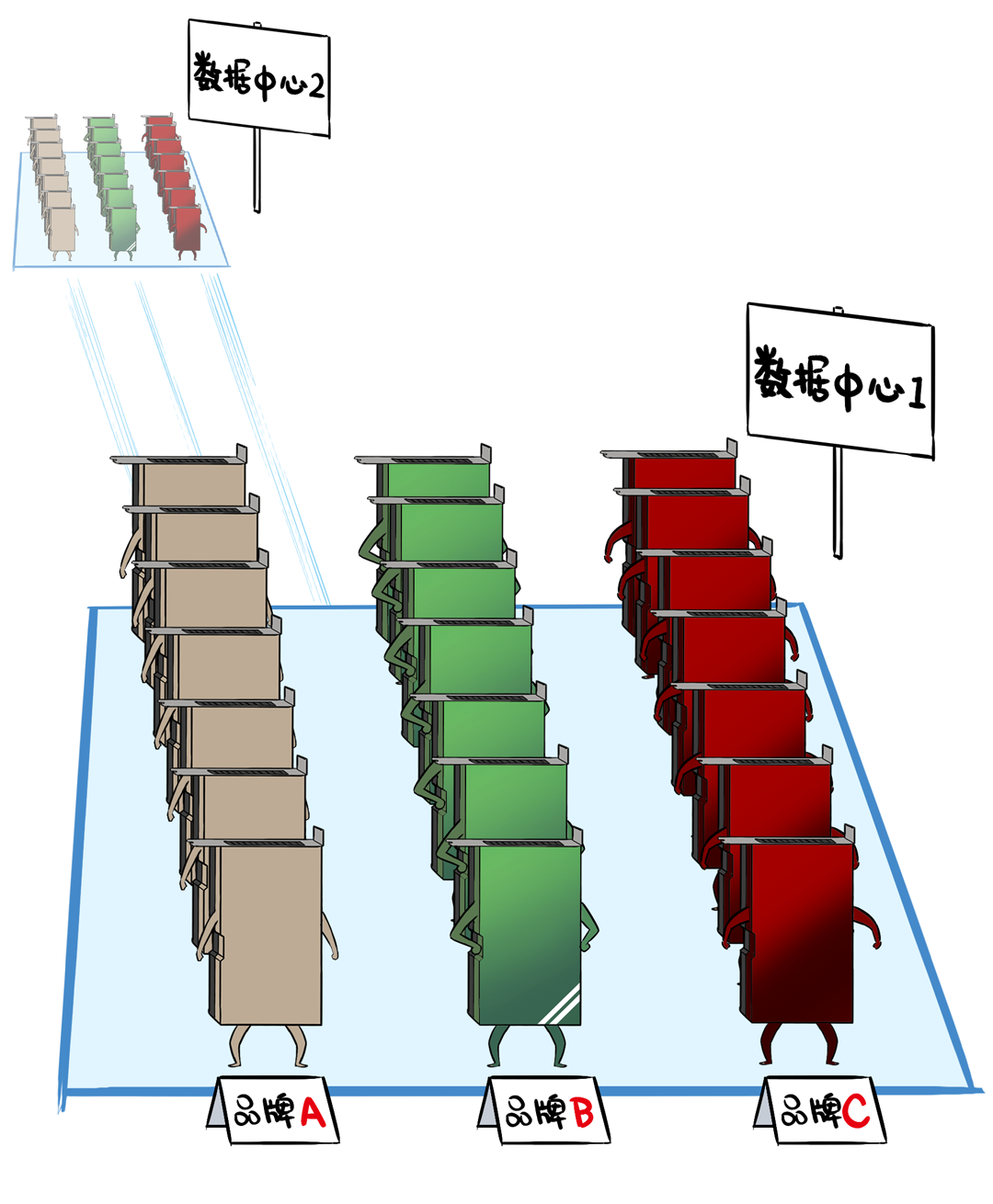
本来跨区域就够难了,再加上夹杂多芯,确实难上加难。
但你大可定心,“多芯”难题,百度百舸早就解决了,上一期咱们就先容过,传送门在这里:《不是GPU买不起,而是多芯夹杂更有性价比》。
还有如何搭建多芯混书册群动画,大众不错沿途温习↓

百度预判了趋势,早早为⼗万卡集群作念好了一切准备:距离不是问题、多芯夹杂不是问题,踏实性捏续加码…
实测数据透露,在百度百舸4.0的加捏之下,100KM以内跨地域范围内历练性能单⼀历练任务,性能折损低于4%,夹杂多芯集群相对单芯集群,历练效力损耗低于5%!
